

CS 510 Image Computation
Spring 2012
CS 510 Assignment 2.
Assignment 2 - Image Comparison and Template Matching.
The ABCs of Cats, Dogs and Owls
Due Monday March 19th Due Thursday March 22nd
Overview
Please submit your assignment as a single zipped file containing code and your report. Upload this file to the Assignment 2 on RamCT. (3/19/12 Ross)
Note, a discussion board has been started on the RamCT site for the course with some suggestions pertaining to this assignment. (3/17/12 Ross)
In this assignment you will be writing code to read and process a series of images in order to excercise your understanding of different image comparison techniques. Along the way material we've covered relative to the Fourier Transforma and PCA will come into play. Keep in mind that in many respects the imagery for this assignment is remarkable simple; toy problems if your will. However, also keep in mind that in the course of carrying out this assignment you should be developing a working understanding of key techniques that are best understood first in terms of relatively simple data.
There are several parts to the assignment. In the first part you will compute pairswise comparisons between a set of 12 images of three characters, "A", "B" and "C". Two distance measures, L1 and L2 will be used, as well as one similarity measure, Pearson Correlation. In the second part you will repeat the process used in part one but using images with background noise added and you will explore possible ways of counter acting the noise. In the third part, PCA techniques will be used to develop subspaces associated with both individual letters as well as all three letters together. The distance/similarity comparisons done in image space will be related to alternatives computed in PCA space. In the fourth part of the assignment you will develop code to detect and clip from a larger image instances of the three words "Cat", "Dog" and "Owl".
The bulk of the work in this assignment involves constructing the code to carry out the tests described below. However, you will also be submitting a written report presenting your results that documents what you've computed and more important learned from the process.
As of Feburary 27th the details for some aspects of the assignment are still under development, so expect elaborations on parts 2 through 4 in the coming days.
All the images for this assignment are available in a zip file.
Part 1: ABCs on Smooth Background.
You are being provided twelve 32 by 32 pixel images of 48pt "A", "B" and "C" characters in Arial and Helvetica fonts and in normal and bold face.
 |
 |
 |
 |
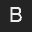 |
 |
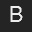 |
 |
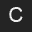 |
 |
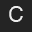 |
 |
To develop a basic understanding of L1, L2 and correlation as techniques for comparing registered images, you are to compute all pairwise distance/similarity values between these 12 images. You will report an ROC curve for each of these three measures comparing the true character recognition rate versus the false recognition (accept) rate.
For this part of the assignment, you must also implement correlation using the approach of transforming both images into the Fourier Domain, taking their product (complex conjugate of second) and then taking the inverse Fourier transform of the result. When you do this, it will become trivial to report a fourth result, that of comparing the maxiumum correlation score between all pairs of images and the associated ROC. As you develop your report, comment upon the relative merits of these four ways of comparing what are in the greater scheme of things relatively trivial images.
Part 2: ABCs on Structured Background.
Begin by repeating all the steps carried out in Part 1 but using the following images.
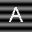 |
 |
 |
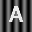 |
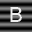 |
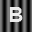 |
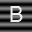 |
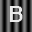 |
 |
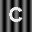 |
 |
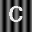 |
Describe the outcome in terms of correctly recognizing characters. Now attempt to modify the comparson process in such a way that the recognition of characters improves and report on your progress. Steer clear of excessivly complex fixes. You are not being asked to jump ahead in the course to techniques involving edge detection, feature detectors, etc. Going to such lengths is not be necessary.
Part 3: ABCs of PCA.
For each set of 12 images associated with Parts 1 and 2 above, construct the PCA subspace in which each of the sets reside. Now repeat the L1, L2 and Pearson Correlation computation in the resulting low (11) dimensional space. How do comparisons in image space relate to what you've computed in Parts 1 and 2 above?
For the Part 2 data with structured backgrounds, how does background pattern relate to the PCA subspace? Working with the PCA subspace representation is there a ready means of improving character recognition performance.
Part 4: Template Matching "Cat", "Dog" and "Owl".
You are being provided six 128 by 128 pixel images for this part of the assignment. The first three are templates, one word per template. The second three include instances of these words at different locations within the larger image.
 |
 |
 |
 |
 |
 |
Write the code needed to generate the correlation surface for each template applied to each test image: nine correlation surfaces in all. Use the correlation peaks to isolate each word and write the code necessary to extract a small square image chip just large enough to enclose the detected words from each of the three test images.
Formalities:
Each student will submit through email a report summarizing their work on this assignment. Students will also submit through email a compressed (zip) file of their source code. Finally, students will then meet one-on-one with the instructor to demonstrate samples of their working code.
Ross Beveridge 2/27/12